How to develop a mobile application with ONNX Runtime
ONNX Runtime gives you a variety of options to add machine learning to your mobile application. This page outlines the general flow through the development process. You can also check out the tutorials in this section:
- Build an objection detection application on iOS
- Build an image classification application on Android
ONNX Runtime mobile application development flow
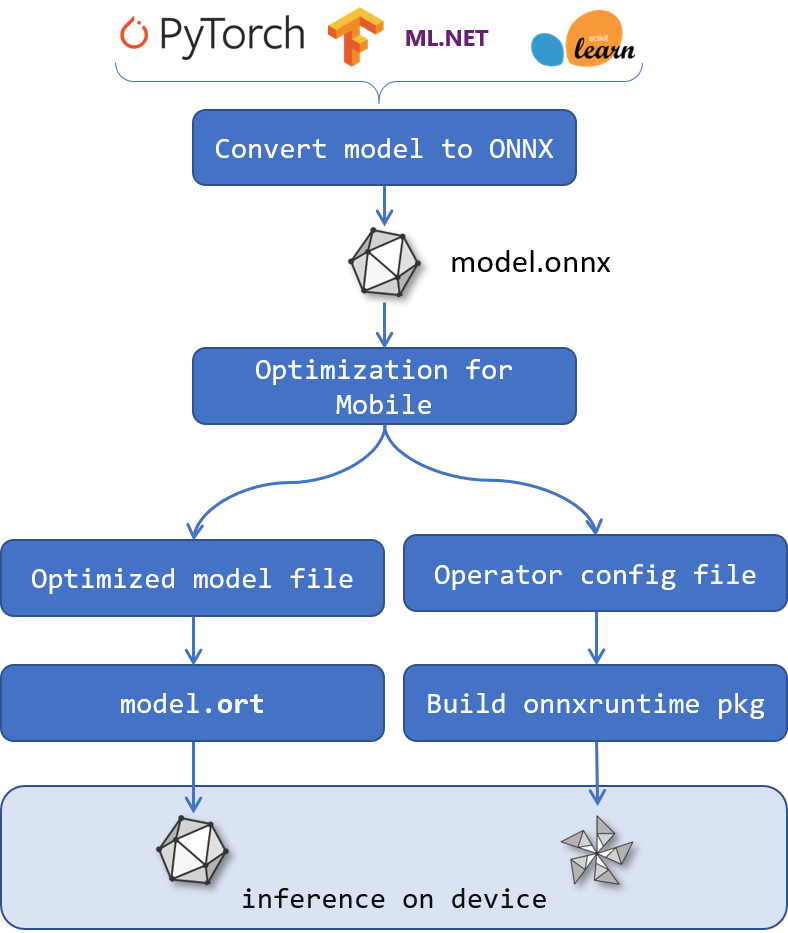
-
Which ONNX Runtime mobile library should I use?
We publish the following ONNX Runtime mobile libraries:
- Android C/C++
- Android Java
- iOS C/C++
- iOS Objective C
-
Which machine learning model does my application use?
You need to understand your mobile app’s scenario and get an ONNX model that is appropriate for that scenario. For example, does the app classify images, do object detection in a video stream, summarize or predict text, or do numerical prediction.
ONNX models can be obtained from the ONNX model zoo, converted from PyTorch or TensorFlow, and many other places.
Once you have sourced or converted the model into ONNX format, there is a further step required to optimize the model for mobile deployments. Convert the model to ORT format for optimized model binary size, faster initialization and peak memory usage.
-
How do I bootstrap my app development?
If you are starting from scratch, bootstrap your mobile application according in your mobile framework XCode or Android Development Kit. TODO check this.
a. Add the ONNX Runtime dependency b. Consume the onnxruntime API in your application c. Add pre and post processing appropriate to your application and model
-
How do I optimize my application?
The execution environment on mobile devices has fixed memory and disk storage. Therefore, it is essential that any AI execution library is optimized to consume minimum resources in terms of disk footprint, memory and network usage (both model size and binary size).
ONNX Runtime Mobile uses the ORT model format which enables us to create a custom ORT build that minimizes the binary size and reduces memory usage for client side inference. The ORT model format file is generated from the regular ONNX model using the
onnxruntimepython package. The custom build does this primarily by only including specified operators and types in the build, as well as trimming down dependencies per custom needs.
Table of contents
- Mobile objection detection on iOS
- Mobile image recognition on Android
- ORT Mobile Model Export Helpers