Optimize and Accelerate Machine Learning Inferencing and Training
Speed up machine learning process
Built-in optimizations that deliver up to 17X faster inferencing and up to 1.4X faster training
Plug into your existing technology stack
Support for a variety of frameworks, operating systems and hardware platforms
Build using proven technology
Used in Office 365, Visual Studio and Bing, delivering half Trillion inferences every day
Please help us improve ONNX Runtime by participating in our customer survey.
Get Started Easily
- Optimize Inferencing
- Optimize Training
Platform
Platform list contains six items
Windows
Linux
Mac
Android
iOS
Web Browser (Preview)
API
API list contains eight items
Python
C++
C#
C
Java
JS
Obj-C
WinRT
Architecture
Architecture list contains five items
X64
X86
ARM64
ARM32
IBM Power
Hardware Acceleration
Hardware Acceleration list contains fifteen items
Default CPU
CoreML
CUDA
DirectML
oneDNN
OpenVINO
TensorRT
NNAPI
ACL (Preview)
ArmNN (Preview)
MIGraphX (Preview)
TVM (Preview)
Rockchip NPU (Preview)
Vitis AI (Preview)
Installation Instructions
Please select a combination of resources
Organizations and products using ONNX Runtime

News & Announcements
Accelerate PyTorch transformer model training with ONNX Runtime – a deep dive
ONNX Runtime (ORT) for PyTorch accelerates training large scale models across multiple GPUs with up to 37% increase in training throughput over PyTorch and up to 86% speed up when combined with DeepSpeed...Read more
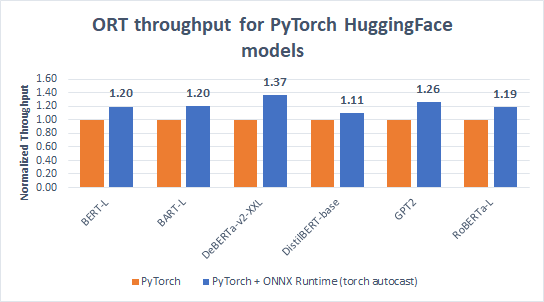
Accelerate PyTorch training with torch-ort
With a simple change to your PyTorch training script, you can now speed up training large language models with torch_ort.ORTModule, running on the target hardware of your choice...Read more
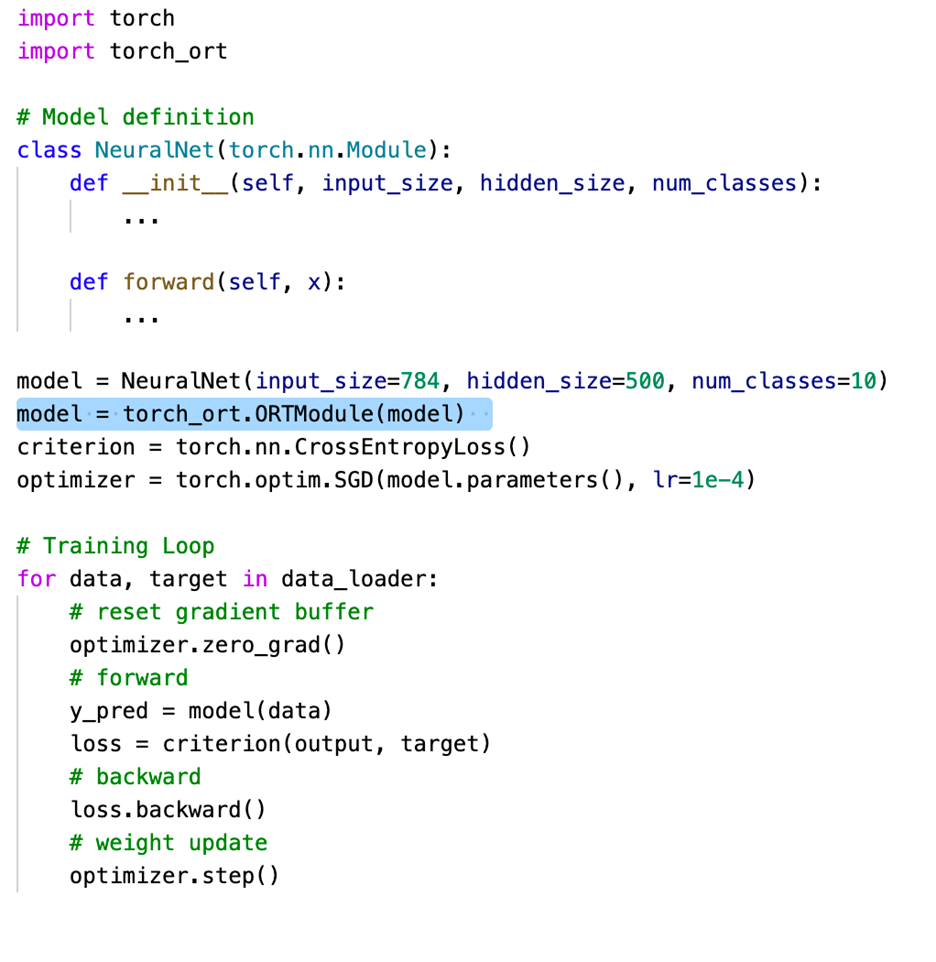
Journey to optimize large scale transformer model inference with ONNX Runtime
Large-scale transformer models, such as GPT-2 and GPT-3, are among the most useful self-supervised transformer language models for natural language processing tasks such as language translation, question answering, passage summarization, text generation, and so on...Read more
ONNX Runtime release 1.8.1 previews support for accelerated training on AMD GPUs with the AMD ROCm™ Open Software Platform
ONNX Runtime is an open-source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms. Today, we are excited to announce a preview version of ONNX Runtime in release 1.8.1 featuring support for AMD Instinct™ GPUs facilitated by the AMD ROCm™ open software platform...Read more

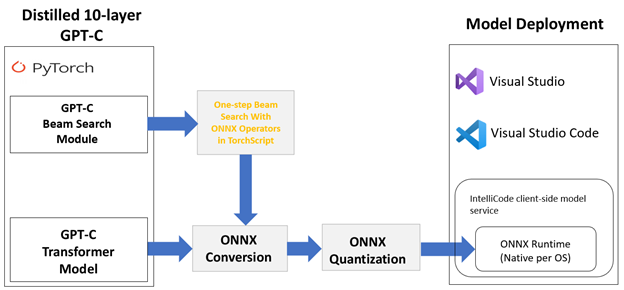
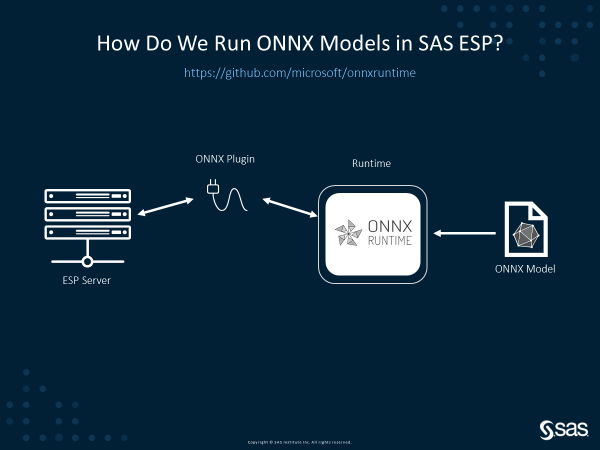
SAS and Microsoft collaborate to democratize the use of Deep Learning Models
Artificial Intelligence (AI) developers enjoy the flexibility of choosing a model training framework of their choice. This includes both open-source frameworks as well as vendor-specific ones. While this is great for innovation, it does introduce the challenge of operationalization across different hardware platforms...Read more
Optimizing BERT model for Intel CPU Cores using ONNX runtime default execution provider
The performance improvements provided by ONNX Runtime powered by Intel® Deep Learning Boost: Vector Neural Network Instructions (Intel® DL Boost: VNNI) greatly improves performance of machine learning model execution for developers...Read more
